Tables
Learn how tables help structure data and how to create them.
Use tables to store raw data you upload to the platform. Each table is defined by a schema which includes columns, names, data types and metadata that organize your information clearly and consistently.
Tables are created at the workspace level, making them accessible across all projects within that workspace. Once your data is stored in tables, you create views to filter and transform that data for specific tasks.
You can create flexible table structures with any number of columns, including nested hierarchical data to match formats from your LIMS or machine outputs. Create multiple tables for different data types or sources as needed.
See an example of how you can use different tables to organize your data below.

Creating tables
Creating tables for your workspace is done with your Customer Success manager. You can also create a table yourself through the API, learn more in /tables.
Table requirements
Tasks have required inputs to be able to run. To be able to create views meeting these requirements your workspace tables must contain specific types of information.
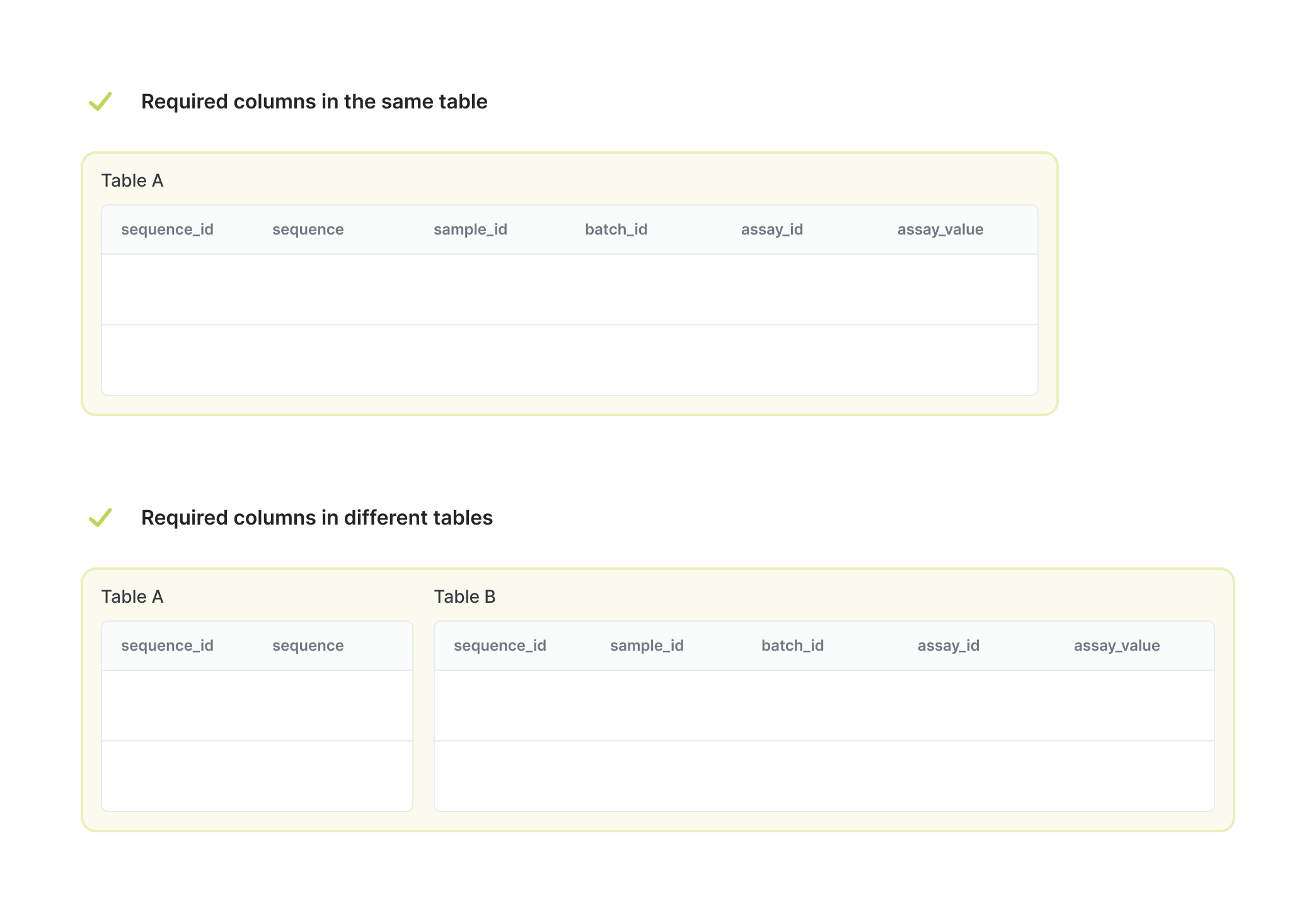
Distributing required columns across tables
Sequence Data: A column containing amino acid sequences for your proteins.
Assay Data: Each assay type represented in its own column. When experimental conditions change for an assay, create a new column and document the updated conditions in the column metadata.
Assay ID: A unique identifier for your assay (e.g. expression_60c).
Sample ID: A unique identifier for each physical protein sample.
Batch ID: An identifier linking measurements to specific experimental batches.
See the example below how you can organize required columns in your workspace tables.
Understanding Sample ID
A Sample ID is a unique identifier assigned to a physical protein sample, serving as the primary reference for all derived samples. It ensures that our machine learning models can accurately link assay values to the correct biological sample, which is essential for model training and improving data quality.
Unlike a Well ID (A1, B2, etc.) that's only unique within a single plate, a Sample ID tracks the same protein variant across multiple experiments, plates, and time points. For example, if you test the same protein variant in three different experiments, it maintains the same Sample ID even when occupying different well positions.
Understanding Batch ID
A batch is a set of assay values measured under comparable experimental conditions. Include a Batch ID to help models distinguish to which batch a measurement belongs. Each batch typically contains a set of controls prepared in a way consistent with the sample.
When to create a new batch:
- Starting a new experiment with freshly purified controls
- Changing experimental conditions that might affect results
- Adding new control samples (like wild type proteins)
Each batch typically includes both your experimental samples and appropriate controls prepared under consistent conditions.
Managing tables
Updating tables
Tables support additive changes only—you can add new columns but cannot remove existing ones. This ensures data consistency for machine learning model training, which requires stable, predictable data formats. Add new columns to a table through the API, learn more in /tables
Archiving tables
If you have tables that you don't use anymore you can archive them through the API, learn more in /tables. Archiving preserves your data and maintains table history—you can unarchive tables anytime through the API.
To permanently delete table data, contact your Customer Success manager.
Table versions
Cradle automatically tracks version history whenever you modify table schemas or data. View this history through both the UI and API to understand how your tables have evolved over time.